Trong mật mã học,
MD5 (viết tắt của tiếng Anh
Message-Digest algorithm 5, giải thuật Tiêu hóa tin 5) là một Bộ tạo Hash mật mã được sử dụng phổ biến với giá trị Hash dài 128-bit. Là một chuẩn Internet (RFC 1321), MD5 đã được dùng trong nhiều ứng dụng bảo mật, và cũng được dùng phổ biến để kiểm tra tính toàn vẹn của tập tin. Một bảng băm MD5 thường được diễn tả bằng một số hệ thập lục phân 32 ký tự.
MD5 được thiết kế bởi Ronald Rivest vào năm 1991 để thay thế cho hàm băm trước đó, MD4. Vào năm 1996, người ta phát hiện ra một lỗ hổng trong MD5; trong khi vẫn chưa biết nó có phải là lỗi nghiêm trọng hay không, những chuyên gia mã hóa bắt đầu đề nghị sử dụng những giải thuật khác, như SHA-1 (khi đó cũng bị xem là không an toàn). Trong năm 2004, nhiều lỗ hổng hơn bị khám phá khiến cho việc sử dụng giải thuật này cho mục đích bảo mật đang bị đặt nghi vấn.
Lịch sử và thuật giải mã
Message Digest là một loạt các giải thuật đồng hóa thông tin được thiết kế bởi Giáo sư Ronald Rivest của trường MIT (Rivest, 1994). Khi công việc phân tích chỉ ra rằng giải thuật trước MD5-MD4- có vẻ không an toàn, ông đã thiết kế ra MD5 vào năm 1991 để thay thế an toàn hơn. (Điểm yếu của MD4 sau đó đã được Hans Dobbertin tìm thấy).
Vào năm 1993, Den Boer và Bosselaers đã tìm ra, tuy còn giới hạn, một dạng "xung đột ảo" của hàm nén MD5; đó là, với hai véc-tơ khởi tạo
I và
J khác nhau 4 bit, dẫn đến:
- MD5compress(I,X) = MD5compress(J,X)
Trong năm 1996, Dobbertin đã thông báo có xung đột của hàm nén MD5 (Dobbertin, 1996). Dù nó không phải là một cuộc tấn công vào toàn bộ hàm băm MD5, nhưng nó đủ gần để các chuyên gia mã hóa đề nghị sử dụng kỹ thuật khác để thay thế, như WHIRLPOOL, SHA-1 hay RIPEMD-160.
Kích thước của bảng băm-128 bit-đủ nhỏ để bị tấn công bruteforce. MD5CRK là một dự án phân bố bắt đầu vào tháng 3 năm 2004 với mục tiêu chứng tỏ rằng MD5 không an toàn trên thực tế bằng cách tìm ra những xung đột sử dụng tấn công bruteforce.
MD5CRK kết thúc nhanh chóng sau ngày 17 tháng 8, 2004, khi xung đột đối với toàn bộ MD5 được công bố bởi Xiaoyun Wang, Dengguo Feng, Xuejia Lai, và Hongbo Yu
[1][2]. Cuộc tấn công phân tích của họ được báo cáo là chỉ diễn ra có một giờ trên nhóm máy IBM p690.
Vào ngày 1 tháng 3 năm 2005, Arjen Lenstra, Xiaoyun Wang, và Benne de Weger đã biểu diễn
[3] việc xây dựng hai giấy phép X.509 với các khóa công cộng khác nhau và cùng bảng băm MD5, một sự xung đột thực thế đáng được trình diễn. Sự xây dựng bao gồm những khóa riêng tư cho cả hai khóa công cộng. Vài ngày sau, Vlastimil Klima đã mô tả
[4] một giải thuật nâng cao, có thẻ xây dựng những xung đột MD5 trong vài giờ với một máy tính xách tay. Vào ngày 18 tháng 3 năm 2006, Klima đã phát hành một giải thuật
[5] có thể tìm thấy đụng độ trong vòng một phút bằng một máy tính xách tay, sử dụng một phương thức mà anh gọi là bắt đường hầm.
Khả năng bị tấn công
Vì MD5 chỉ dò qua dữ liệu một lần, nếu hai tiền tố với cùng bảng băm được xây nên, thì cùng một hậu tố có thể cùng được thêm vào để khiến cho đụng độ dễ xảy ra. Tức là hai dữ liệu vào (input) X và Y hoàn toàn khác nhau nhưng có thể ra (output) được một md5 hash giống nhau . Tuy nhiên xác suất để xảy ra điều này là khá nhỏ.
Vì những kỹ thuật tìm đụng độ hiện nay cho phép các trạng thái băm trước đó được xác định một cách ngẫu nhiên, có thể tìm thấy xung đột đối với bất kỳ tiền tố mong muốn nào; có nghĩa là, đối bất kỳ một chuỗi các ký tự X cho trước, hai tập tin đụng độ có thể được xác định mà đều bắt đầu với X.
Tất cả những gì cần để tạo ra hai tập tin đụng độ là một tập tin mẫu, với một khối dữ liệu 128 byte được xếp trên giới hạn 64 byte, có thể thay đổi tự do bằng giải thuật tìm va chạm.
Vừa rồi, một số dự án đã tạo ra "bảng cầu vồng" MD5 có thể dễ dàng tiếp cận trực tuyến, và có thể được dùng để dịch ngược nhiều bảng băm MD5 thành chuỗi mà có thể đụng độ với đầu nhập gốc, thường dùng với mục đích bẻ mật khẩu.
Ứng dụng
Các đồng hóa MD5 được dùng rộng rãi trong các phần mềm trên toàn thế giới để đảm bảo việc truyền tập tin được nguyên vẹn. Ví dụ, máy chủ tập tin thường cung cấp một checksum MD5 được tính toán trước cho tập tin, để người dùng có thể so sánh với checksum của tập tin đã tải về. Những hệ điều hành dựa trên nền tảng Unix luôn kèm theo tính năng MD5 sum trong các gói phân phối của họ, trong khi người dùng Windows sử dụng ứng dụng của hãng thứ ba.
Tuy nhiên, hiện nay dễ dàng tạo ra xung đột MD5, một người có thể tạo ra một tập tin để tạo ra tập tin thứ hai với cùng một checksum, do đó kỹ thuật này không thể chống lại một vài dạng giả mạo nguy hiểm. Ngoài ra, trong một số trường hợp checksum không thể tin tưởng được (ví dụ, nếu nó được lấy từ một lệnh như tập tin đã tải về), trong trường hợp đó MD5 chỉ có thể có chức năng kiểm tra lỗi: nó sẽ nhận ra một lỗi hoặc tải về chưa xong, rất dễ xảy ra khi tải tập tin lớn.
MD5 được dùng rộng rãi để lưu trữ mật khẩu. Để giảm bớt sự dễ thương tổn đề cập ở trên, ta có thể thêm salt vào mật khẩu trước khi băm chúng. Một vài hiện thực có thể áp dụng vào hàm băm hơn một lần-xem làm mạnh thêm khóa.
Giải thuật
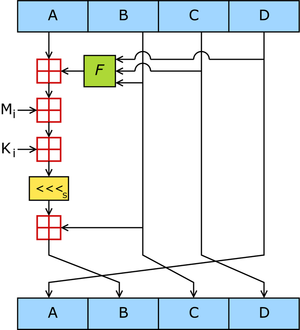
Hình 1. Một thao tác MD5—MD5 bao gồm 64 tác vụ thế này, nhóm trong 4 vòng 16 tác vụ.
F là một hàm phi tuyết; một hàm được dùng trong mỗi vòng.
Mi chỉ ra một khối tin nhập vào 32-bit, và
Ki chỉ một hằng số 32-bit, khác nhau cho mỗi tác vụ.
 s
s chỉ sự xoay bit về bên trái
s đơn vị;
s thay dổi tùy theo từng tác vụ.

chỉ cộng thêm với modulo 2
32.
MD5 chuyển một đoạn thông tin chiều dài thay đổi thành một kết quả chiều dài không đổi 128 bit. Mẩu tin đầu vào được chia thành từng đoạn 512 bit; mẩu tin sau đó được độn sao cho chiều dài của nó chia chẵn cho 512. Công việc độn vào như sau: đầu tiên một bit đơn, 1, được gắn vào cuối mẩu tin. Tiếp theo là một dãy các số zero sao cho chiều dài của mẩu tin lên tới 64 bit ít hơn so với bội số của 512. Những bit còn lại được lấp đầy bằng một số nguyên 64-bit đại diện cho chiều dài của mẩu tin gốc.
Giải thuật MD5 chính hoạt động trên trạng thái 128-bit, được chia thành 4 từ 32-bit, với ký hiệu
A,
B,
C và
D. Chúng được khởi tạo với những hằng số cố định. Giải thuật chính sau đó sẽ xử lý các khối tin 512-bit, mỗi khối xác định một trạng thái. Quá trình xử lý khối tin bao gômg bốn giai đoạn giống nhau, gọi là
vòng; mỗi vòng gồm có 16 tác vụ giống nhau dựa trên hàm phi tuyến
F, cộng mô đun, và dịch trái. Hình 1 mô tả một tác vụ trong một vòng. Có 4 khả năng cho hàm
F; mỗi cái được dùng khác nhau cho mỗi vòng:
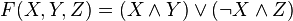



/////////////////Đoạn này do NDC thêm vào////////////////////////
Đây là quá trình thực hiện xử lý của 4 hàm F, G, H, I ở trên:
Vòng 1 (Round 1): Ký hiệu [abcd k s t] là bước thực hiện của phép toán a = b + ((a + F(b, c, d) + X[k] + T[t]) <<< s) Quá trình thực hiện 16 bước sau:
[ABCD 0 7 1] [DABC 1 12 2] [CDAB 2 17 3] [BCDA 3 22 4]
[ABCD 4 7 5] [DABC 5 12 6] [CDAB 6 17 7] [BCDA 7 22 8]
[ABCD 8 7 9] [DABC 9 12 10] [CDAB 10 17 11] [BCDA 11 22 12]
[ABCD 12 7 13] [DABC 13 12 14] [CDAB 14 17 15] [BCDA 15 22 16]
Giải thích: ví dụ biểu thức thứ 2 là [DABC 1 12 2], tương đương với:
D = A + ((D + F(A,B,C) + X[1] + T[2]) <<< 12) Nhận xét: Vòng 1 dùng hàm F, Với giá trị t từ 1 -> 16 và k từ 1 -> 15
Vòng 2 (Round 2): Tương tự, ký hiệu [abcd k s t] là của biểu thức : a = b + ((a + G(b, c, d) + X[k] + T[t]) <<< s) Quá trình thực hiện 16 bước :
[ABCD 1 5 17] [DABC 6 9 18] [CDAB 11 14 19] [BCDA 0 20 20]
[ABCD 5 5 21] [DABC 10 9 22] [CDAB 15 14 23] [BCDA 4 20 24]
[ABCD 9 5 25] [DABC 14 9 26] [CDAB 3 14 27] [BCDA 8 20 28]
[ABCD 13 5 29] [DABC 2 9 30] [CDAB 7 14 31] [BCDA 12 20 32]
Nhận xét: Vòng 2 dùng hàm G, với t từ 17 -> 32 và k = 1 + 5k mod 16
Vòng 3 (Round 3):
Tương tự, ký hiệu [abcd k s t] là của biểu thức : a = b + ((a + H(b, c, d) + X[k] + T[t]) <<< s)
Quá trình thực hiện 16 bước:
[ABCD 5 4 33] [DABC 8 11 34] [CDAB 1 16 35] [BCDA 14 23 36]
[ABCD 1 4 37] [DABC 4 11 38] [CDAB 7 16 39] [BCDA 10 23 40]
[ABCD 13 4 41] [DABC 0 11 42] [CDAB 3 16 43] [BCDA 6 23 44]
[ABCD 9 4 45] [DABC 12 11 46] [CDAB 5 16 47] [BCDA 2 23 48]
Nhận xét: Vòng 3 dùng hàm H, với t từ 33 -> 48 và k =5 + 3k mod 16
Vòng (Round 4):
Tương tự, ký hiệu [abcd k s t] là của biểu thức:
a = b + ((a + I(b,c,d) + X[k] + T[t]) <<< s)
Quá trình thực hiện 16 bước :
[ABCD 0 6 49] [DABC 7 10 50] [CDAB 14 15 51] [BCDA 5 21 52]
[ABCD 12 6 53] [DABC 3 10 54] [CDAB 10 15 55] [BCDA 1 21 56]
[ABCD 8 6 57] [DABC 15 10 58] [CDAB 6 15 59] [BCDA 13 21 60]
[ABCDb 4 6 61] [DABC 11 10 62] [CDAB 2 15 63] [BCDA 9 21 64]
Nhận xét: Vòng 4 dùng hàm I, với t từ 49 -> 64 và k =7k mod 16
/* Sau đó làm các phép cộng sau. ( Nghĩa là cộng vào mỗi thanh ghi giá trị của nó trước khi vào vòng lặp ) */
A = A + AA
B = B + BB
C = C + CC
D = D + DD
End /* of loop on i */
Bước 5 : Tính kết quả message digest. Sau khi thực hiện xong bước 4, thông điệp thu gọn nhận được từ 4 thanh ghi A, B, C, D, bắt đầu từ byte thấp của thanh ghi A và kết thúc với byte cao của thanh ghi D bằng phép nối như sau: Message Digest = A || B || C || D. ( || phép toán nối)
///////////////////////////////////////////////////////////////////////

lần lượt chỉ phép XOR, AND, OR và NOT.
Mã giả
Mã giả cho giải thuật MD5 như sau.
//Chú ý: Tất cả các biến đều là biến không dấu 32 bit và bao phủ mô đun 2^32 khi tính toán
var int[64] r, k
//r xác định số dịch chuyển mỗi vòng
r[ 0..15] := {7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22}
r[16..31] := {5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20}
r[32..47] := {4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23}
r[48..63] := {6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21}
//Sử dụng phần nguyên nhị phân của sin của số nguyên làm hằng số:
for i from 0 to 63
k[i] := floor(abs(sin(i + 1)) × (2 pow 32))
//Khởi tạo biến:
var int h0 := 0x67452301
var int h1 := 0xEFCDAB89
var int h2 := 0x98BADCFE
var int h3 := 0x10325476
//Tiền xử lý:
append "1" bit to message
append "0" bits until message length in bits ≡ 448 (mod 512)
append bit (bit, not byte) length of unpadded message as 64-bit little-endian integer to message
//Xử lý mẩu tin trong đoạn 512-bit tiếp theo:
for each 512-bit chunk of message
break chunk into sixteen 32-bit little-endian words w[i], 0 ≤ i ≤ 15
//Khởi tạo giá trị băm cho đoạn này:
var int a := h0
var int b := h1
var int c := h2
var int d := h3
//Vòng lặp chính:
for i from 0 to 63
if 0 ≤ i ≤ 15 then
f := (b and c) or ((not b) and d)
g := i
else if 16 ≤ i ≤ 31
f := (d and b) or ((not d) and c)
g := (5×i + 1) mod 16
else if 32 ≤ i ≤ 47
f := b xor c xor d
g := (3×i + 5) mod 16
else if 48 ≤ i ≤ 63
f := c xor (b or (not d))
g := (7×i) mod 16
temp := d
d := c
c := b
b := b + leftrotate((a + f + k[i] + w[g]) , r[i])
a := temp
//Thêm bảng băm của đoạn vào kết quả:
h0 := h0 + a
h1 := h1 + b
h2 := h2 + c
h3 := h3 + d
var int digest := h0 append h1 append h2 append h3 //(expressed as little-endian)
//định nghĩa hàm dịch trái
leftrotate (x, c)
return (x << c) or (x >> (32-c));
Ghi chú: Thay vì hàm hóa RFC 1321 gốc như trên, phần sau có thể được dùng để tăng độ hiệu quả (hữu ích nếu ngôn ngữ assembly được dùng - còn không, chương trình dịch sẽ tự động tối ưu hóa đoạn mã ở trên):
(0 ≤ i ≤ 15): f := d xor (b and (c xor d))
(16 ≤ i ≤ 31): f := c xor (d and (b xor c))
Các bảng băm MD5
Bảng băm MD5 128 bit (16 byte) (còn được gọi là
message digests) được biểu diễn bằng chuỗi 32 số thập lục phân. Sau đây cho thấy đầu vào ASCII 43 byte và bảng băm MD5 tương ứng:
MD5("The quick brown fox jumps over the lazy dog")
= 9e107d9d372bb6826bd81d3542a419d6
Thậm chí một sự thay đổi nhỏ trong mẩu tin cũng dẫn đến thay đổi hoàn toàn bảng băm, do hiệu ứng thác. Ví dụ, thay
d thành
e:
MD5("The quick brown fox jumps over the lazy eog")
= ffd93f16876049265fbaef4da268dd0e
Bảng băm của một chuỗi rỗng là:
MD5("")
= d41d8cd98f00b204e9800998ecf8427e
 08:50
08:50
 Unknown
Unknown

 Nghỉ/Cách khoảng
Nghỉ/Cách khoảng Bằng số
Bằng số Sai
Sai Hủy bỏ
Hủy bỏ A / 1
A / 1 B / 2
B / 2 C / 3
C / 3 D / 4
D / 4 E / 5
E / 5 F / 6
F / 6 G / 7
G / 7 H / 8
H / 8 I / 9
I / 9 J
J K / 0
K / 0 L
L M
M N
N O
O P
P Q
Q R
R S
S T
T U
U V
V W
W X
X Y
Y Z
Z




































